Database recovery
posted Friday July 11th @ 2:55pm
About three weeks ago, my old Pipe Ten hosting account came up for renewal. Being far too clever to pay for something I don't use any more, I told the guys to cancel my account.
A week later, my website went down. As did my travel diary site. And a couple of other sites. I'd forgotten I was still using the old databases.
Pipe Ten don't keep backups more than 24 hours so that was out, especially as an ex-customer. Once I'd stopped crying, I got pragmatic. Could I perhaps find the data in Google Cache? I still had all the image files, I just needed the text and the titles and some kind of relationship between them and the image numbers. As the diary runs on a script, even the formatted output should be uniform and hence perfectly suited to data mining with a few regular expressions..
I did a quick search and found that, amazingly, some pages were right there in Google Cache! I quickly wrote the following script:
<?
for ($i=533;$i<1020;$i++) {
$fp = fopen('file'.$i.'.htm','w');
$url = urlencode('http://carl.pappenheim.net/d/'.$i);
fwrite($fp,implode('',file('http://216.239.59.104/search?q=cache:'.$url)));
fclose($fp);
}
?>
It ran! Within about a minute, all 700-odd entries (don't ask why they start from 533, they just do) were ripped to my hard drive. I clicked on the first few and they all looked sound. Then I looked at one about halfway down.
We're sorry...
... but your query looks similar to automated requests from a computer virus or spyware application. To protect our users, we can't process your request right now.
We'll restore your access as quickly as possible, so try again soon. In the meantime, if you suspect that your computer or network has been infected, you might want to run a virus checker or spyware remover to make sure that your systems are free of viruses and other spurious software. Curses, foiled! Only about 100 pages had downloaded before Google got wise to my scheme. I inserted a strpos() check for part of their error message and let it run. My access was only restored the following morning, after about ten hours. This was going to take a week, and that wasn't taking into account the 2,000-odd travel diary entries I had to find as well. Now what?
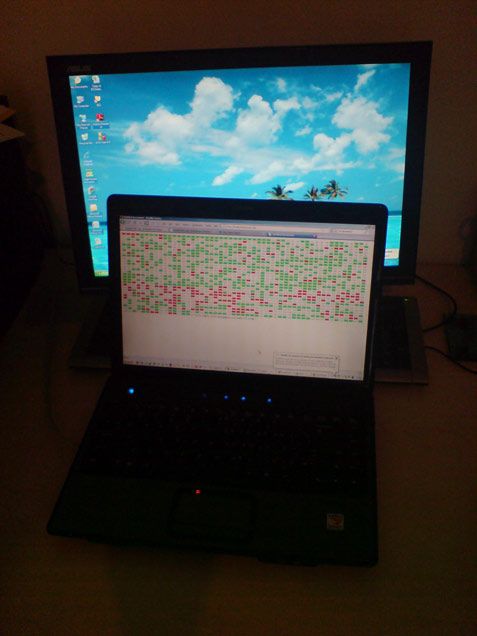
Eventually, I rewrote the script to show all the page numbers and, through AJAX, hit for each one after a random number of seconds. No matter how slowly I went, 100 or so every half day or so seemed to be the limit. Sometimes the delay for a reset was twelve hours, sometimes as little as two, but it was always a hundred or so in a row before I got kicked off and it was slow going. I randomised the fetch order, in case they were watching for sequential requests - no improvement. I guessed they were blocking by IP so I tried walking up the high street, begging five minutes' access from several different people but that became exhausting. Eventually, Luca came to the rescue with his 3G data card. Every time you connect, you get a new IP! This worked a treat and I sat there for about an hour, connecting and disconnecting while the little green and red numbers (for successful and unsuccessful page fetches respectively) popped up on the page. The full fetch script is
here if you're interested.
From there, a few simple (har har) regex operations retrieved all the data and now the diary is back, comments and all! Now I just have to get cracking on those travel diaries. With the map co-ordinates.
Spang.
Comment on this entry